
From Black Box to Blueprint: Tracing the Logic of Claude 3.5
Exploring the Hidden Anatomy of a Language Model
In the age of large language models, capability often outpaces comprehension. Models like Claude 3.5 can write poetry, solve logic puzzles, and navigate multilingual queries — but we still don’t fully understand how. Beneath their fluent outputs lies a vast architecture of layers, weights, and attention heads that, until recently, remained largely inscrutable.
Anthropic’s 2025 research article “On the Biology of a Large Language Model” dares to open this black box. Through a new interpretability method called attribution graphs, the researchers illuminate the circuits of thought inside Claude 3.5 Haiku — a compact, efficient version of the Claude model family.
Attribution graphs act like neuroscience for transformers. They trace which internal components causally influence which outputs, revealing not just what a model does, but how it does it. The paper doesn’t just offer another set of metrics — it offers a microscope.
Dissecting Reasoning: Where Thinking Begins
Multi-step Reasoning
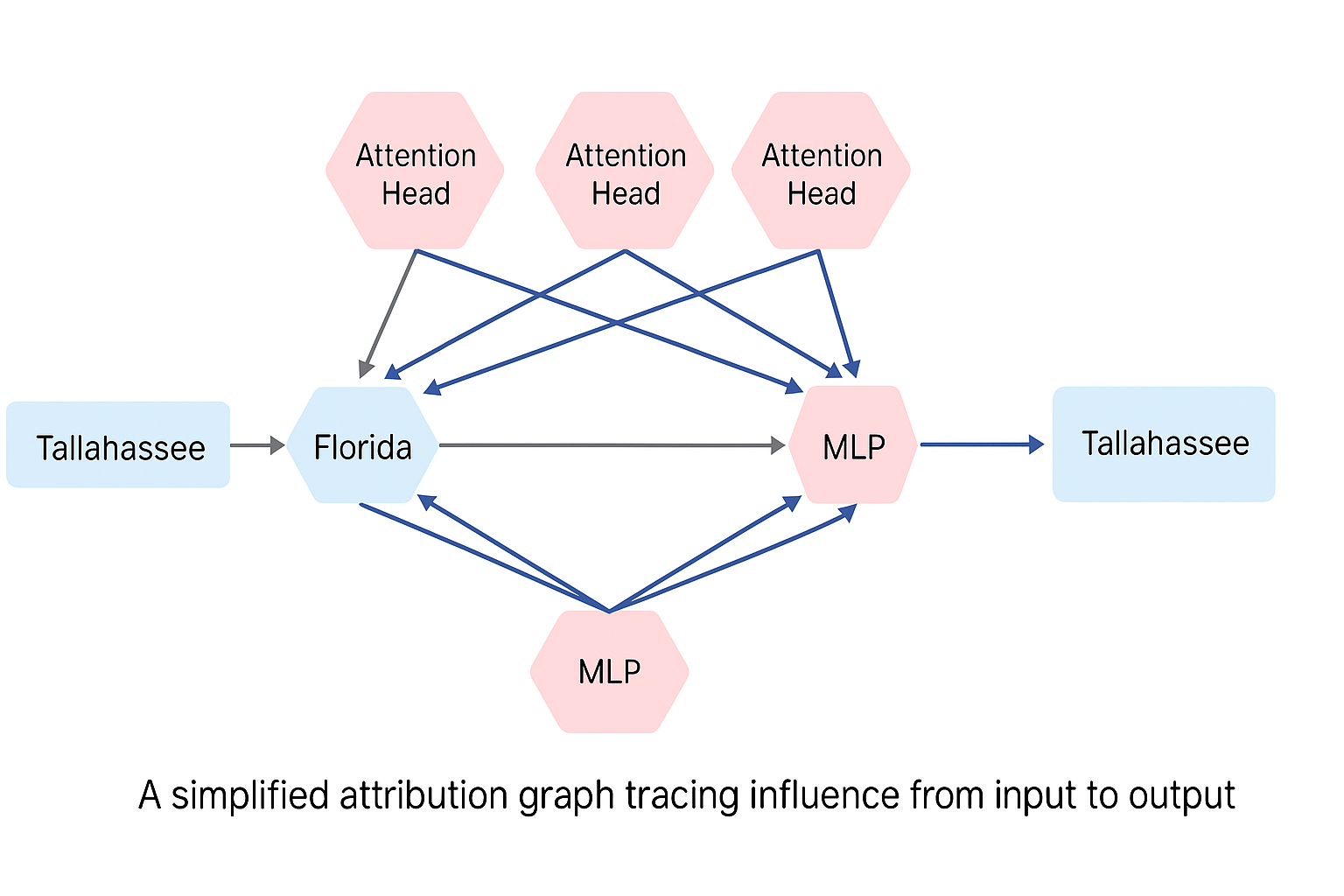
In one example, the model is asked:
“What is the capital of the state where Tallahassee is?”
This is not a simple question — it requires multi-hop reasoning. First, the model must identify that Tallahassee is in Florida. Then, it must find Florida’s capital. Attribution graphs show that Claude 3.5 does not arrive at the answer in one shot — instead, distinct intermediate circuits activate sequentially, each solving a subproblem.
This reveals that the model has learned compositional logic — the ability to chain steps, reuse knowledge, and build answers piece by piece. Such decomposition is not trivial; it reflects a level of internal abstraction we often associate with higher reasoning in humans.
Generating with Foresight: The Poetic Circuit
Planning Rhymes Ahead
Claude 3.5 doesn’t just generate rhymes — it strategizes. When producing verse, it often selects rhyming end-words before writing the first syllable of a line. Attribution graphs reveal pre-activation of rhyme-related nodes that determine the endpoint of a poetic phrase early in generation.
This behavior mirrors how poets work: we choose a rhyme target, then retroactively fit the rest of the line. Claude demonstrates similar behavior, a sign of temporal abstraction and goal-aware planning — skills far beyond simple token prediction.
Thinking Multilingually
Language-Specific vs. Language-General Circuits
Claude’s multilingual prowess isn’t magic — it’s modular. Attribution graphs reveal two coexisting types of circuits:
- Language-specific circuits: tailored for syntactic quirks (e.g., negation in French or Spanish).
- Language-general circuits: abstract logic and reasoning that transfer across languages.
This dual architecture allows the model to scale across tongues without catastrophic forgetting. Like the bilingual brain, Claude uses shared pathways for universal meaning, and unique ones for grammatical finesse.
Logical Routines in Math
Arithmetic Through Circuit Reuse

Claude handles arithmetic not through rote memory, but through structured internal routines. When solving problems like 123 + 456, attribution graphs reveal reusable submodules that:
- Detect position (hundreds, tens, units)
- Handle carrying logic
- Generalize to unseen problems
These circuits are activated consistently across different addition tasks. The takeaway? Claude doesn’t memorize math — it simulates it. Much like a student mastering base-10 arithmetic, it builds an internal “mental abacus.”
⚠The Shadows of Intelligence
Medical Diagnosis and Hallucination
Claude 3.5 performs decently on medical triage tasks — identifying diseases from symptoms. However, attribution graphs show that some answers arise from shallow pattern matching, not deep understanding.
In one case, the model links “rash + joint pain” to lupus correctly. But when prompted with nonsensical combinations, the same circuits still confidently suggest real diseases. These hallucinations emerge from entity-retrieval heads that prioritize resemblance over reasoning.
This underscores a core risk: surface similarity ≠ semantic understanding.
Jailbreaks and Safety Circuit Failures
Claude is trained to refuse unethical or dangerous requests using refusal heads. These activate when prompts are clearly malicious. But attribution graphs show that adversarial phrasing can reroute computation, bypassing safety entirely.
This demonstrates that security in LLMs must be more than rule-based. It requires robust reasoning about intent, not just input form. Attribution graphs make such vulnerabilities transparent — a powerful tool for red-teaming and patching.
Chain-of-Thought: True or Justified?
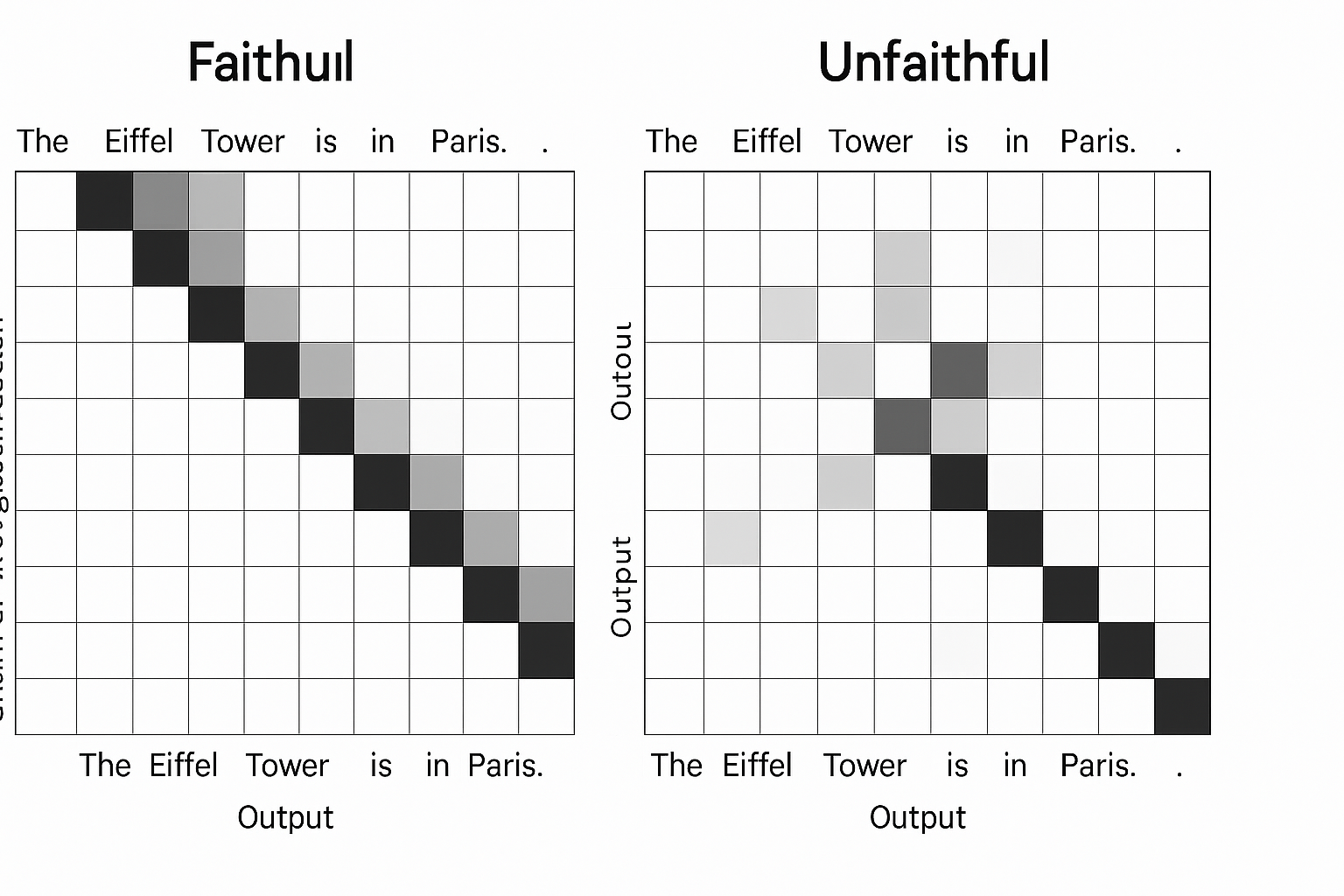
Claude can produce thoughtful-looking step-by-step reasoning. But attribution graphs let us test: is this reasoning real, or post-hoc?
In faithful examples, the intermediate tokens directly influence the final answer. In others, the conclusion is generated first, and the steps are rationalized afterward — a kind of LLM “confabulation.”
Distinguishing between these two modes is critical in trust-sensitive domains. Attribution graphs are a diagnostic lens for evaluating reasoning fidelity.
Internal Modularity: The Brain Inside the Model
Just like biological organisms have organs, Claude has modular functional units. Attribution graphs identify components for:
- Synonym detection
- Number line reasoning
- Capital-city lookup
- Refusal filtering
- Translation equivalence
This modularity promotes circuit reuse, debuggability, and even future extensibility — such as plugging in improved calculators or fact-checkers.
Which Parts Do What?
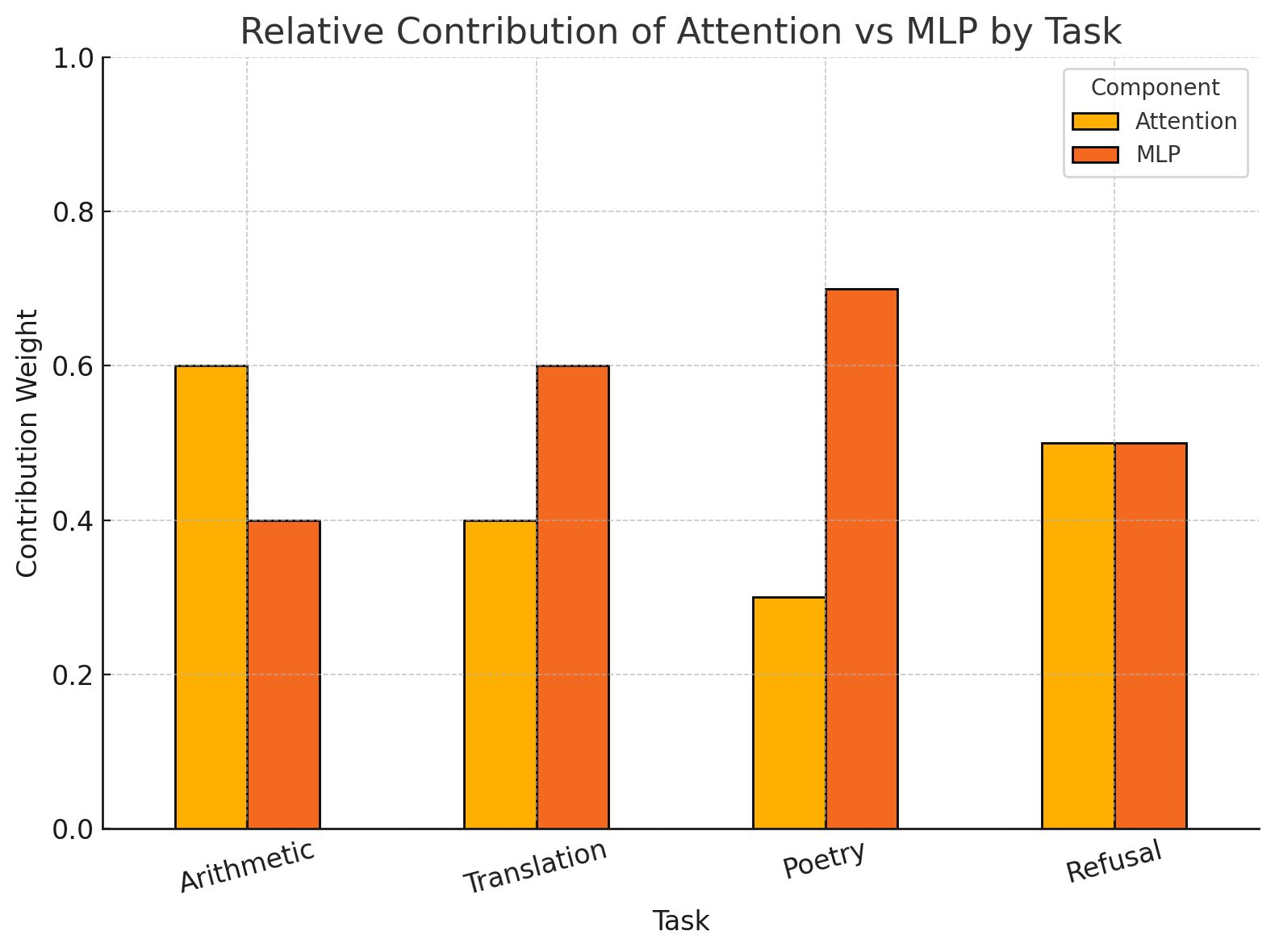
Different heads and layers specialize. Arithmetic relies more on MLPs, while translation is attention-heavy. Refusals activate specific safety heads, while poetry uses forward-predictive layers.
This analysis allows targeted pruning, feature localization, and alignment tuning. We’re not just training Claude — we’re mapping its mind.
Evolution of Thinking
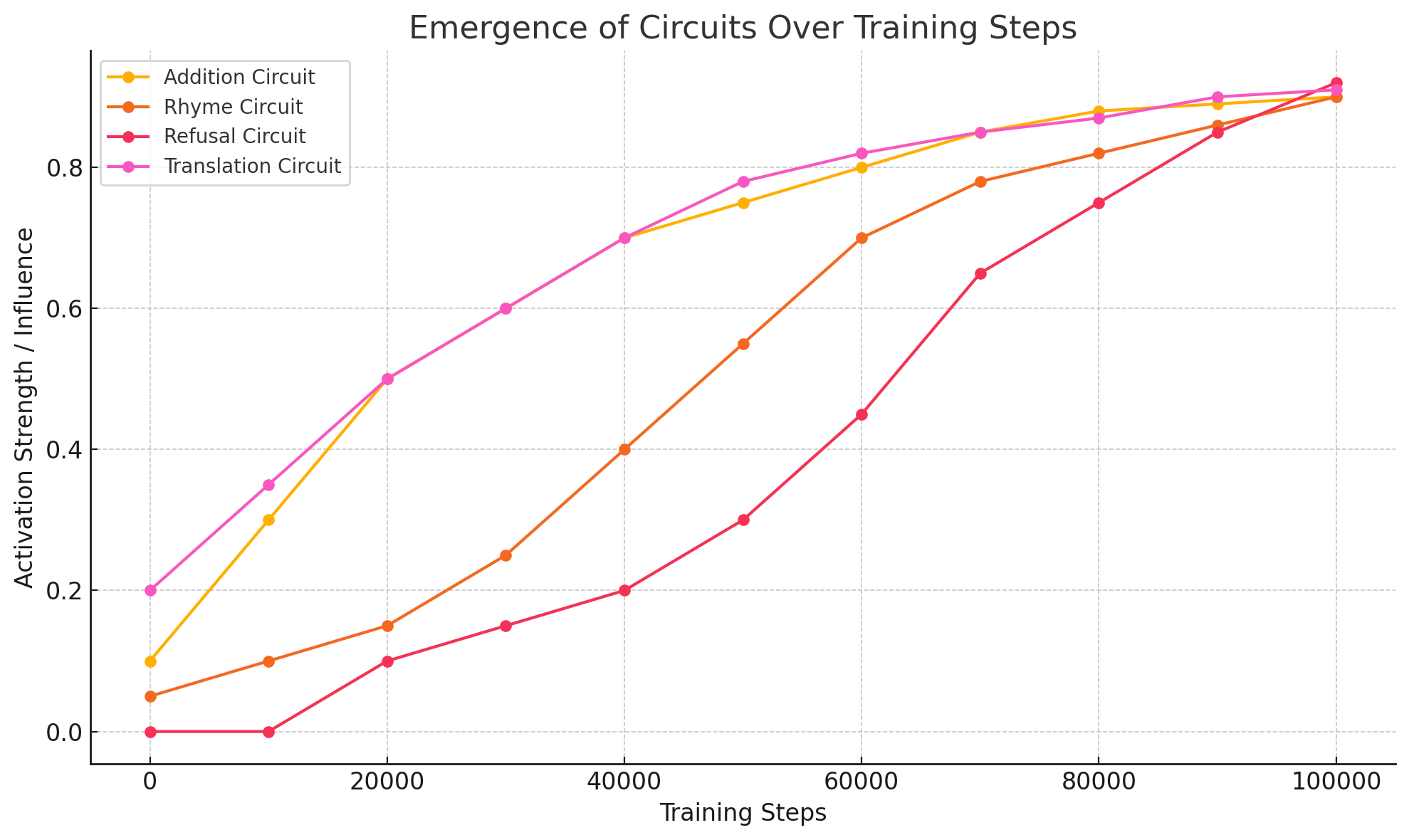
Claude’s circuits don’t appear fully formed. Attribution over training epochs shows:
- Early emergence of arithmetic
- Gradual formation of refusal gates
- Late specialization of rhyme planning
This insight paves the way for interpretable curriculum learning and tracking capability alignment over time.
Token-Level Influence
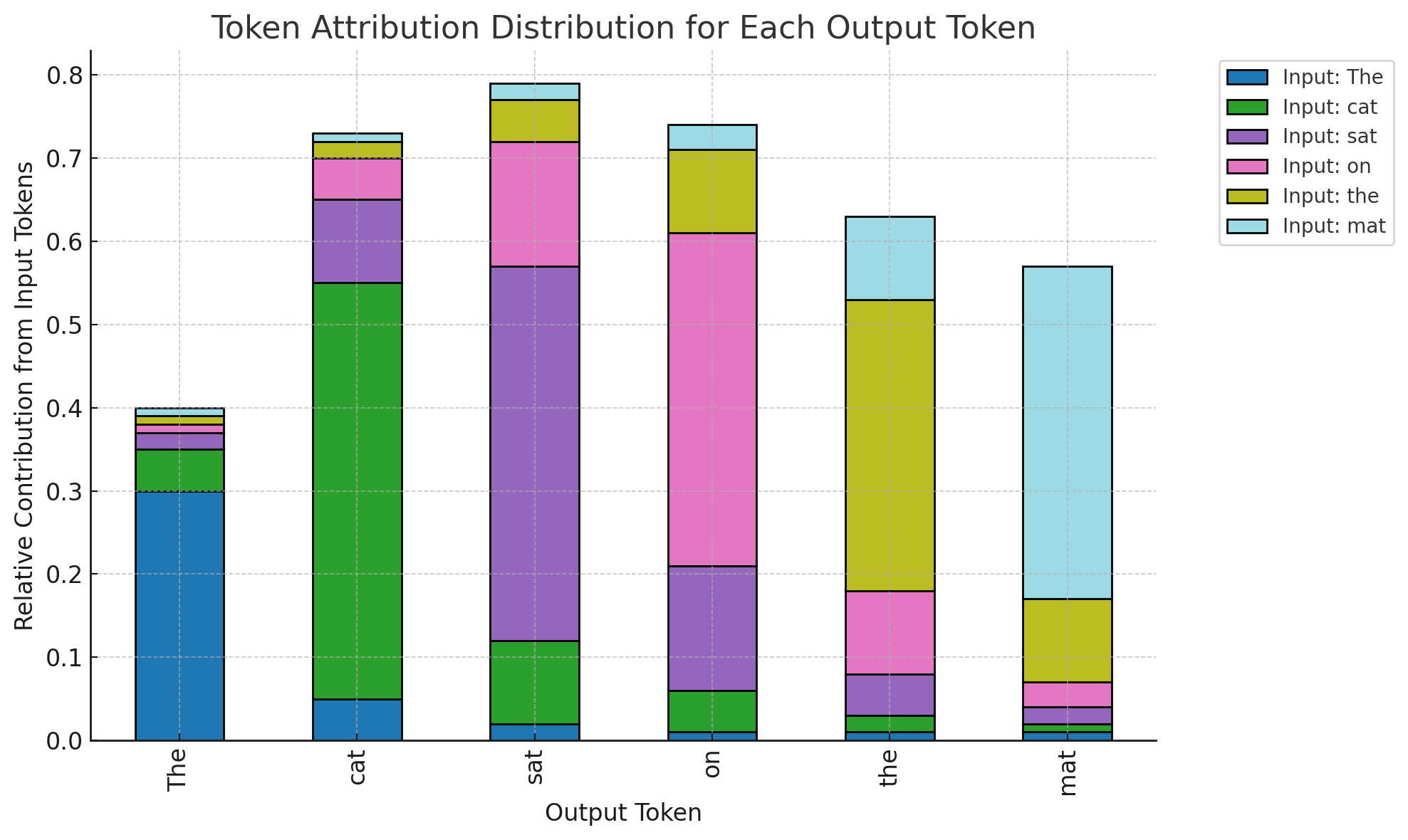
In a simple sentence like “The cat sat on the mat,” attribution shows how each token is shaped by others. Such visualizations demystify:
- Why certain completions appear
- How coherence is maintained
- Which prompts cause drift or bias
What This Paper Solves
The power of this paper lies in what it unlocks:
- Traceability: You can see why a model answered the way it did
- Modularity: You can isolate functional blocks inside the model
- Diagnostics: You can catch hallucinations, jailbreaks, and misalignment
- Faithfulness: You can verify whether a model’s reasoning is real
It moves interpretability from “feeling” to function.
Attribution Error Analysis
These frameworks help categorize common interpretability failures:
- Faithful but wrong
- Unfaithful but confident
- Certainty mismatches
- Distraction by irrelevant inputs
Having a taxonomy like this is the first step toward automated auditing.
Final Reflection
Claude 3.5 Haiku is more than a model — it’s a system of circuits. What Anthropic’s paper reveals is that LLMs are not black boxes by nature — only by neglect.
With attribution graphs, we move toward responsible AI science — grounded, visual, modular, and aligned with how we understand complex systems in nature.
For researchers, this is a landmark paper. For builders, it’s a blueprint. For the curious, it’s a new way to peer into digital cognition.